今天收到朋友要求,做一个工作,做一个件软件 ,关于数据抓取 ODDS.500.COM
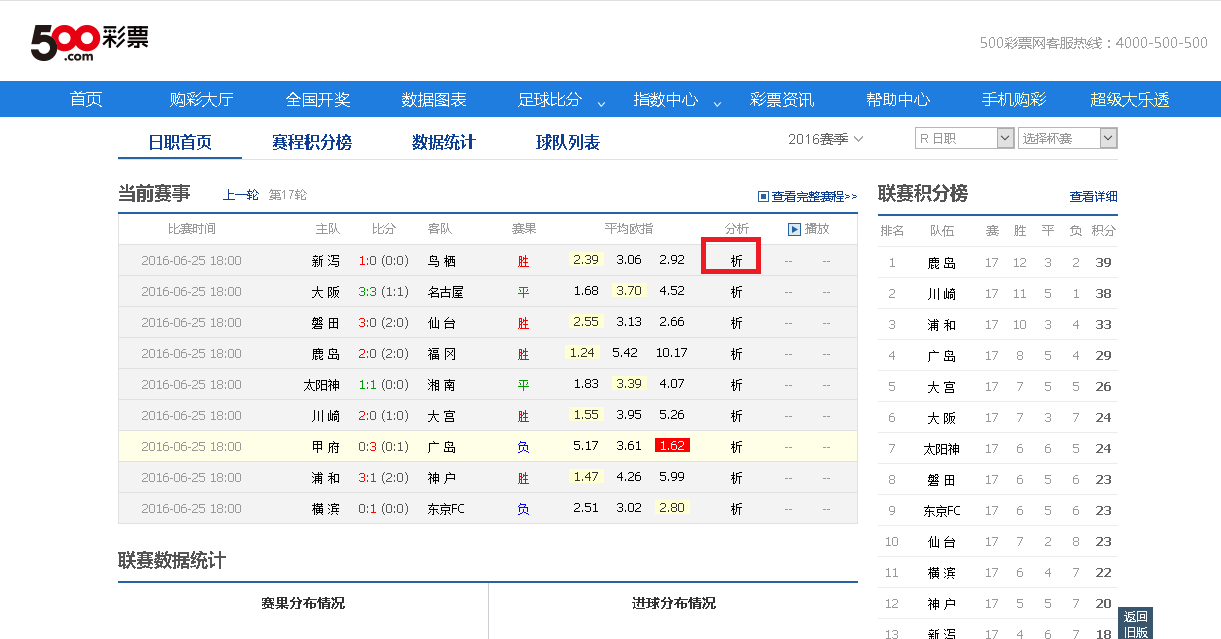
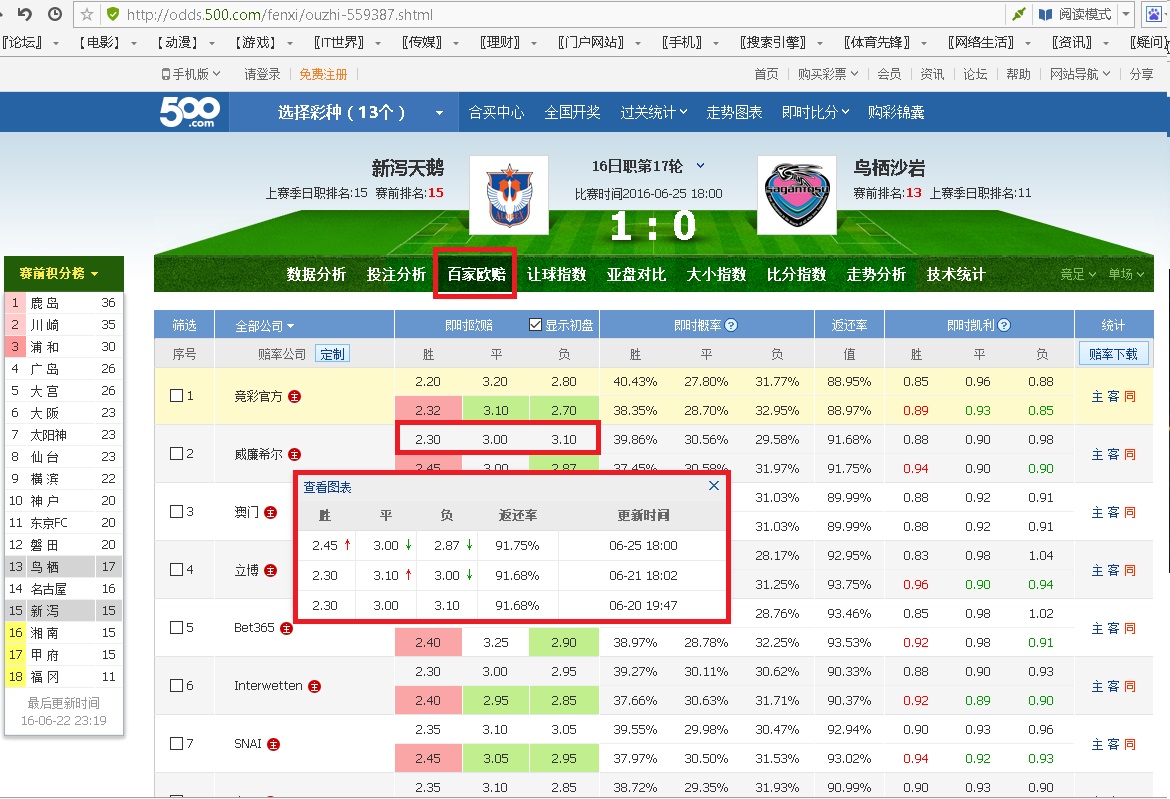
先来说说如果手工操作是这样的,打开网址 http://liansai.500.com/zuqiu-3748/ 点击分析,进去百家欧赔,再点一个公司,就看到这个公司历史的赔率。
抓取各公司赔率的历史变化
下面开始工作,
第一个界面很简单
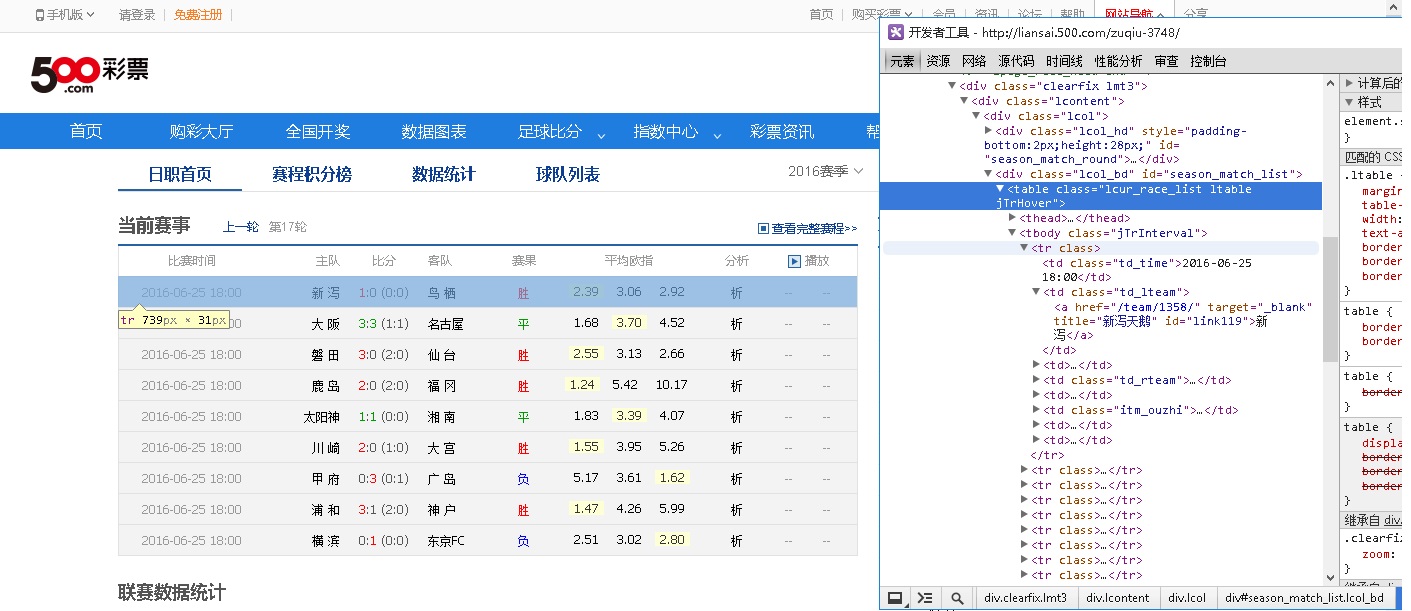
随便一个浏览器输入网址得到HTML代取,截取就可以了。得到关键信息,{开场时间,主队名称,客队名称,这场比赛的ID号}
网址 http://odds.500.com/fenxi/ouzhi-这场比赛的ID号.shtml 就是第二页了。
第二个界面就难多了,进去后,发现动条,往下走,数据才加载出来吧,好吧,我认为打开打开,并不会得到全部的数据,必须发送数据过去。打开跟踪后发现果然如此
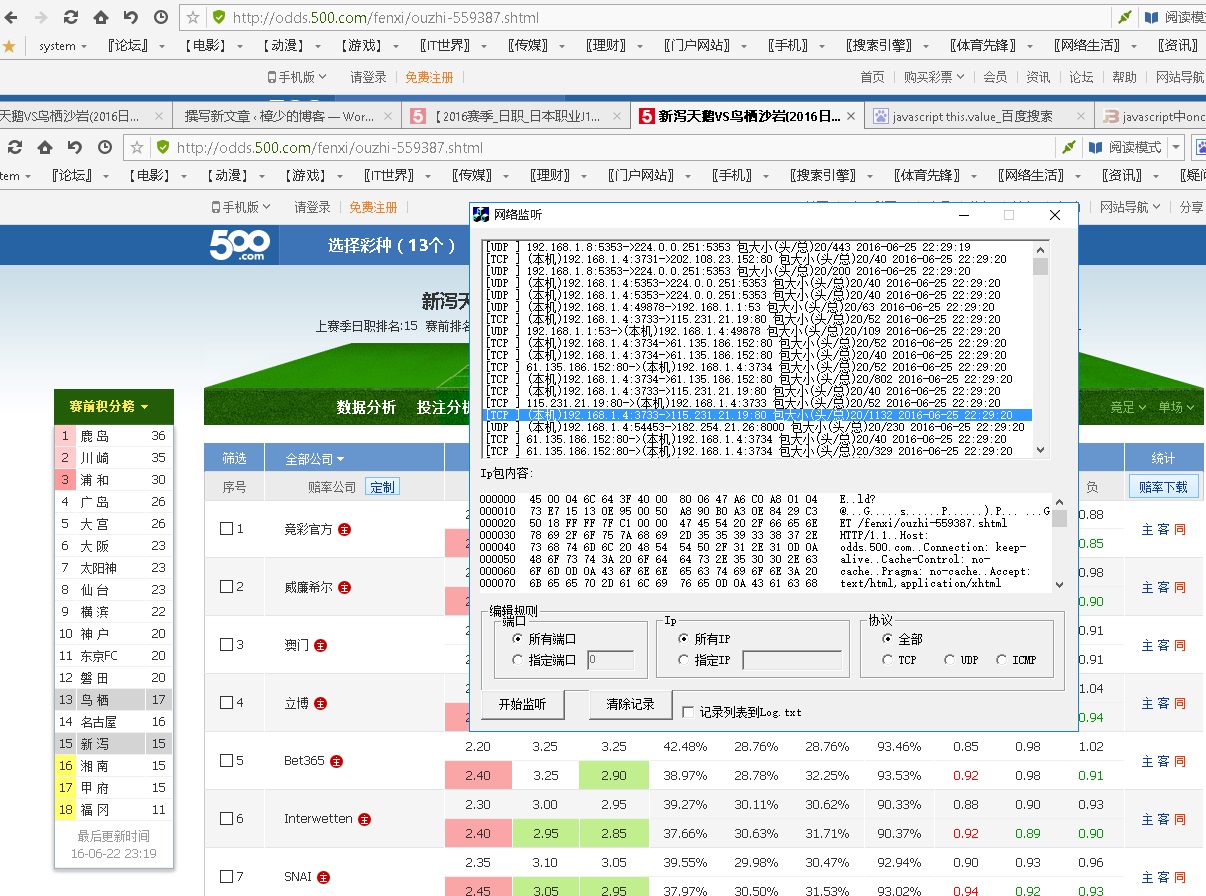
发送了这个数据包。
而很不幸运的时,返回来的数据包,压缩过的,估计是没有 加密的。
看来下一步要先研究出解压,并且加载后面部分的数据的方法先。
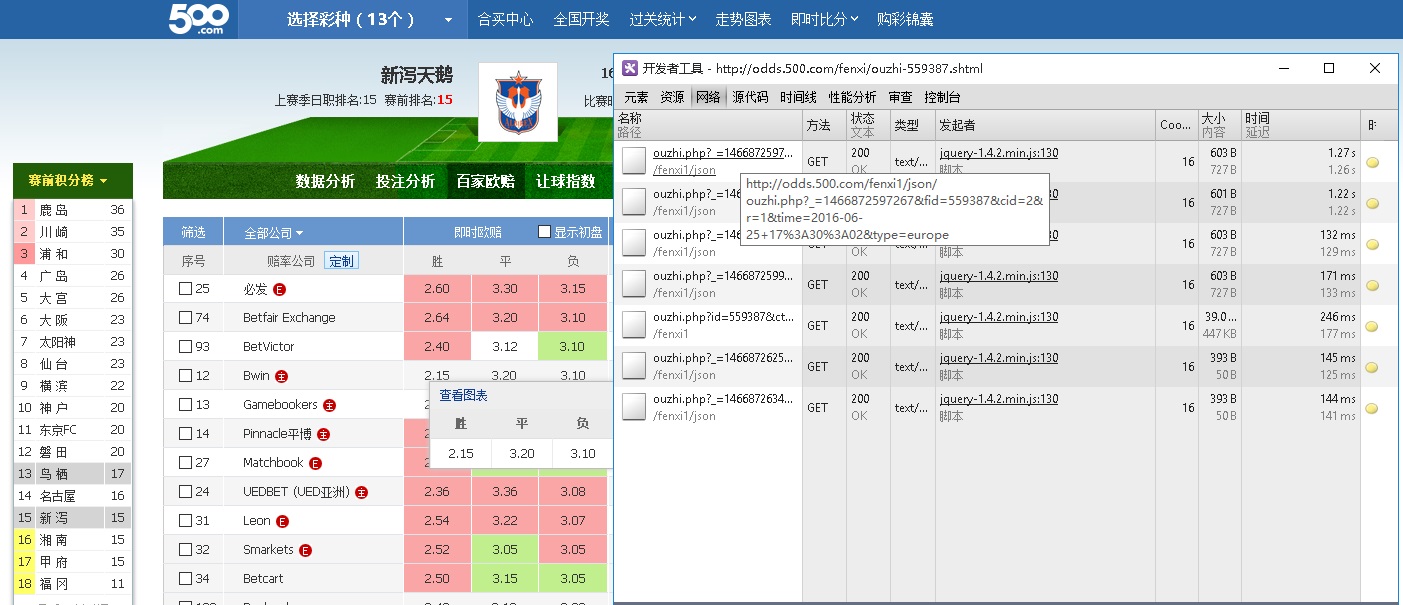
后来还是浏览器的F12方便,直接看到请求,
http://odds.500.com/fenxi1/json/ouzhi.php?_=1466871817505&fid=559387&cid=1&r=1&time=2016-06-25+16%3A36%3A36&type=europe
获取到最后的明细了,这就是点击出来的历史赔率
未完, 待续,。